Page: https://cs.uwaterloo.ca/~lapchi/cs341/index.html
Instructor: Lap Chi LAU
Time: W,F 11:20am-12:50pm EST
computation model
eg. graph problem on n vertices -> use bits to label vertices (assume they fit into a word)
eg. binary search done in assumes constant random access
eg. (3-sum) have n numbers and a target number c, find indices i, j, k such that or report that such triples do not exist.
algo1: observe this can be rewritten as , idea: enumerate all pairs and check whether for some k.
sort(a)
for i = 1, n:
for j = 1, n:
if binary_search(a, c-a[i]-a[k]) is not nullptr:
report them
runtime:
(in worst case, hashing does not guarantee constant retrieval)
algo2: this can be rewritten as idea: enumerate all pairs and check whether for some pair i, j.
sort(a)
for k = 1, n:
// solve 2-sum problem in O(n) given a sorted array
runtime:
eg. (2-sum) have n numbers (sorted!) and a target number b, find indices i, j such that or report that such pairs do not exist.
b = 19:
|1 |4 |6 |8 |9 |11|14|20|
^ ^
L R
auto L = 1
auto R = n
while L <= R: // allow equal
auto sum = a[L] + a[R]
if sum == b:
report L, R
else if sum > b:
--R
else:
--L
nope
runtime: each iteration R-L decreases by 1, hence at most n iterations => O(n).
proof of correctness:
see CS240 (recursion tree)
lecture this time says T(n) = cnlogn (tree has logn levels) - why?
eg.
in the recursion tree, each level has , , , , ..., (increasing). the order is dominated by the leaf level.
eg.
in the recursion tree, each level has , , , ... (decreasing). the order is dominated by the root level.
eg. mergesort , the sequence is non-changing. order is the sum of all levels.
theorem. (master theorem) consider where constant (a is integer). then let
proof.
at the root level, work done is , next level: , next level: , ....
at the leaf level, the problem size should be bounded by constant ie for the level number i. we then have . eg we can let . the number of leaves is .
the work done on each level is a geometric sequence with ratio .
eg. .
note . the work done on each level is 1, so the total work = # levels. at bottom level i we have for bound . this means as long as i is this large the problem size is bounded to this constant. we have .
eg. .
eg. given n distinct numbers , give the number of "inversion" pairs with .
|3|7|2|5| |9|1|6|4|
^ ^
i j -- crossing pair
// idea 2
count_sort(A[n]):
if n == 1:
return 0
int n1 = count_sort(A[1 : n/2]) // T(n/2)
int n2 = count_sort(A[n/2+1 : n]) // T(n/2)
int nm = merge_count(A) // T(n)
return n1 + nm + n2
merge_count(A[n]):
int sum = 0
// same as merge_sort's merge function
// there are two ptrs l and r at the start of each sub array
// whenever we put one value from right array at r, this means on the left array,
// elements from l to end are bigger than it. hence we add the # of these values
// to sum.
return sum
idea 1 in total uses .
idea 2 in total uses .
eg. given n numbers , find i, j that maximizes .
|1|-2|3|-4|5|4| |2|3|1|-3|-2|-1|
///// /////// -- max left & right sum
runtime: . (this is not the best)
eg. given n points on the 2d plane, find a pair that minimizes .
-δ L δ
. | .
. . | . . .
. . | .
. | .
|
-δ L δ
|
+---+---|---+---+
| | | | |
+---+---|---+---+
| . | . | . | . |
+---+---|---+---+
| . | . | . | . |
+---+---|---+---+
| . | p | . | . | . are candidate points
+---+---|---+---+
| | | | |
+---+---|---+---+
|
the algo:
runtime:
where do we use the assumption x being distinct?
eg. given two n-bit binary numbers , find ab.
Karatsuba's algorithm
eg. given matrices , find AB.
Strassen's algorithm two multiply two matrices , we divide it into 4 submatrices , and
where
runtime: . if , it is faster than normal algorithm.
puzzle: determine whether a graph contains triangles. hint: for each entry in Adj^i, it is the # of i-length paths. check Adj with Adj^2.
eg. have n distinct numbers , find the median.
eg. relaxed: have n distinct numbers, find the k-th smallest number.
runtime: .
we use this method to find the pivot in linear time:
median of medians
puzzle: what if we divide into groups of 3, 7, 9, ..., .
adjacency matrix vs. adjacency list
defn. two vertices are connected if there is a path from to .
defn. a subset of vertices is connected if are connected for all .
defn. a graph is connected if are connected for all .
defn. a connected component is maximally connected subset of vertices.
eg. determine whether a graph is connected.
pick s, run bfs. then graph is connected iff visited[v] = true for all v.
eg. find all connected components of a graph.
pick s, run bfs to find reachable vertices. this is one component. then do the same for remaining vertices. (O(n + m))
eg. determine whether two vertices u, v are connected.
run bfs from u, check visited[v] = true.
eg. find shortest path between two vertices u, v. see next!
motivation: ask friend networks eg.
// G = (V, E), s ∈ V
// output: reachable vertices from v
reachable_vertices(G, s):
auto visited = {v: false for v in G.V}
auto Q = new queue
Q.enqueue(s)
visited[s] = true
while Q is not empty:
auto u = Q.dequeue()
for each v in u:
if not visited[v]:
Q.enqueue(v)
visited[v] = true
return [v for v, b in visited if b]
runtime: each vertex is enqueued at most once, when we dequeue a vertex u, then the for loop is run deg(n) steps. total time: . (recall handshake lemma: sum of degrees = 2*number of edges)
correctness:
how to trace out from a path from s to v?
sproof.: use induction. base case is one vertex, clear. then in every for loop, we already have a tree (parent dict), we encounter a new unvisited child vertex, then we are just extending from a leaf vertex (as parent) to the current child, hence we maintain the tree. (|E|=|V|-1)
for shortest path: when we enqueue & dequeue vertices from the queue, the 1-distance vertices will always be in the front (because we discovered them early, and we are using a queue), and then 2-distance... (closer vertices always in the front) we are also building a tree in this order, so this tree-building traversal should reflect the shortest path.
eg.
// G = (V, E), s ∈ V
bfst(G, s):
auto visited = {v: false for v in G.V}
auto Q = new queue
auto parent = {}
auto distance = {}
Q.enqueue(s)
visited[s] = true
parent[s] = nullptr
distance[s] = 0 // not necessary
while Q is not empty:
auto u = Q.dequeue()
for each v in u:
if visited[v]:
continue
Q.enqueue(v)
visited[v] = true
parent[v] = u
distance[v] = distance[u] + 1
defn. a graph is bipartite if there is a bipartition of such that all edges have one endpoint in and one endpoint in .
eg. check whether a graph is bipartite.
runtime: O(|V|+|E|).
correctness:
remark.
motivation: find path from s to t in a maze
dfs(G, s):
auto visited = {v: false for v in G.V}
visited[s] = true
explore(u):
for v in u:
if not visited[v]
visited[v] = true
explore(v)
explore(s)
return [v for v, b in visited if b]
how to trace out from a path from s to v?
defn. usual root, parent, ancestor, descendant
defn. a non-tree edge uv is called a back edge if either u is an ancestor or descendant of v. (in the graph)
theorem. in an undirected graph, all non-tree edges are back edges.
proof. it is sufficient to show it is impossible to have an edges that connects two leaf nodes in the tree (thus the only way is to connect back to the ancestor). suppose u and v are leaves, and u is in a subtree rooted at t. case 1: t is not done and we are at u, if we connect uv, then they have parent-child relation, and uv would be in-tree. case 2: t is done, then we backtrack to the node t and continue exploring its next child trees, then tv have parent-child relation.
we can record the time when a vertex is first visited and when a vertex finished exploring:
auto visited = {v: false for v in G.V}
visited[s] = true
auto start = {}
auto finish = {}
auto time = 1
explore(u):
start[u] = time++
for v in u:
if not visited[v]
visited[v] = true
explore(v)
finish[u] = time++
explore(s)
theorem. (parenthesis) the intervals [start[u], finish[u]] and [start[v], finish[v]] are either disjoint or one interval contains the other.
proof.
suppose is connected,
find all cut vertices and cut edges.
claim. in the dfs, a subtree below is a connected component in iff there are no edges with one endpoint in and another endpoint in an ancestor of .
proof:
hence we only need to consider a few cases.
lemma. for a non-root vertex in a dfs tree, is a cut vertex iff there is a subtree below with no edges going to an ancestor of .
proof:
lemma. for the root vertex in a dfs tree, is a cut vertex iff has at least two children.
proof:
idea: for each subtree rooted at v, find the vertex that is reached by back edges from that is closest to root.
how to find cut edges? tree edge uv is cut edge iff low[v] > start[u]; back edges can never be cut edge.
defn. if is a directed edge, then is the tail and is the head.
defn. the in-degree of a vertex , , is the number of edges with being the head. is source if indeg is 0.
defn. the out-degree of a vertex , , is the number of edges with being the tail. is sink if outdeg is 0.
defn. a directed graph is a directed acyclic graph if there is no directed cycle.
defn. is reachable from if there is a directed path from to .
defn. a directed graph is strongly connected if for every pair of vertices , is reachable from and is reachable from .
defn. a subset is called strongly connected if for every pair of vertices , is reachable from and is reachable from (path can go outside)
defn. a subset is a strongly connected component if $S is a maximally strongly connected subset. ie S is strongly connected but S+v is not for any .
eg. determine if a graph is strongly connected.
eg. determine if a graph is a DAG.
eg. find all strongly connected components of a directed graph.
both DFS and BFS are same as undirected graphs, except that we only explore out-neighbors.
given a graph G=(V,E), return yes if G is strongly connected.
claim. G is strongly connected iff every vertex is reachable from s and s is reachable from every vertex , where s is arbitrary.
proof.
claim. given , we reverse the direction of all edges to obtain . then there is a path from v to s in G iff there is a path from s to v in .
algo:
runtime: O(n+m)
eg. find shortest walk from s to t with odd length.
copy the graph and have odd vertices and even vertices. find path from even s to odd t.
given a graph G=(V,E), return yes if it is DAG.
prop. if a directed graph is acyclic, then one can find a vertex with indegree of 0.
proof. suppose otherwise that all vertices in G has indegree at least 1. to prevent a directed cycle, we must have vertices laid out like: , the middle ones have indegree >= 1. when we run out of vertices, we cannot extend this pattern further, so we could only go backward. as all vertices must have indegree >= 1, we have to go back to but that would form a directed cycle.
defn. a topological ordering is an ordering of vertices such that all edges go forward.
prop. a directed graph is acyclic iff there exists a topological ordering of the vertices.
proof.
algo:
runtime: O(n+m) (kahn's algo)
theorem. (parenthesis) the intervals [start[u], finish[u]] and [start[v], finish[v]] are either disjoint or one interval contains the other.
proof. same as undirected.
lemma. if G is DAG, then for any edge uv, finish[v] < finish[u] for any dfs.
proof.:
algo:
runtime: O(n+m)
find all strongly connected components of a directed graph.
claim. two strongly connected components must be vertex-disjoint.
proof. otherwise the common vertex reaches and is reachable from all vertices in both components, then the two 'components' are not maximal, and we actually only have one strongly connected component.
observation. contracting each strongly connected component results in a DAG (otherwise components are not maximal).
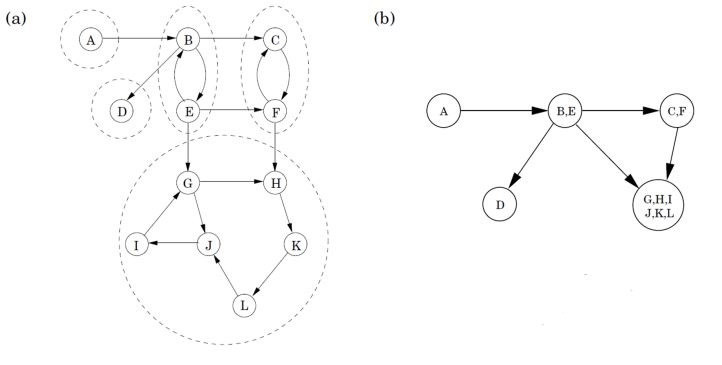
observation. suppose we start a bfs/dfs on a 'sink component', then we can identify the vertices in that sink component. (eg GHIJKL)
lemma. if are strongly connected components and there are directed edges from to , then the largest finishing time in is larger than the largest finishing time in .
proof.
observation. if we have the topological ordering (decreasing finishing time), then do dfs again using this ordering, then we will always first visit an 'ancestor component' before visiting a 'descendant component'.
algo
runtime: O(m+n)
work by using simple and/or local rules to make decisions and then commit on them.
have n jobs with processing times , find an ordering of the jobs to finish so as to minimize the total completion time, where the completion time of a job is defined as time time when it is finished.
| 2 | 5 | 6 | 7 | 8 |
2 7 13 20 28
correctness: if it is not in non-decreasing order, then we want to show the solution is not optimal. then there exists an adjacent inversion pair, p[i] > p[i+1]. if we flip these two jobs, we can know that the sum completion times of all other jobs are the same (and after because p[i]+[i+1] does not change). for these two jobs, the time for old ordering is p[i]+p[i]+p[i+1], in the new ordering, it is p[i+1]+p[i+1]+p[i]. the new ordering is better.
have n jobs, each with processing time and weight . find an ordering of the jobs to finish so as to minimized to total weighted completion time, where weighted completion time of a job is defined as its weight * its completion time.
| 2 | 3 | 7 |
2 5 36 total: 43
| 7 | 2 | 3 |
21 9 12 total: 42
given n intervals , find the maximum subset of disjoint intervals.
there are multiple natural greedy algos:
algo:
runtime: O(nlogn + n)
claim. there exists an optimal solution with chosen.
proof. suppose there exists an optimal solution S that does not include . suppose further the first interval in S conflicts with . because has smallest finishing time, it is earlier than the second interval in S. we can swap the first interval with and the result is still optimal.
lemma. there is an optimal solution using the first k intervals of the greedy solution for any k.
proof. use induction on k. when k=1, this is the above claim. otherwise since we use disjoint intervals, we reuse the above argument.
if the number of intervals in solution is l, we apply the lemma with k=l.
given n intervals , find a coloring of the intervals using the minimum # of colors possible, so that each interval gets one color and any two overlapping intervals get different colors.
algo:
correctness: it is sufficient to show if the algo returns k colors, it is because at one moment there are k intervals pairwise overlapping with each other.
t
------|- 1
----|-- 2
-----|----- 3
--|--- k current interval I_i
since all these intervals contain the start time (we sorted by start time), there are k intervals, so we need k.
defn. we construct prefix code so that no encoding string is a prefix of another encoded string.
given n symbols, with frequencies . find a binary decoding tree T with n leaves that minimizes (average length of encoded strings).
observation. any optimal binary decoding tree is full (every internal node is two children).
proof. because we can just delete the violating internal node without affecting disambiguation.
r r
/ /
_ => w
/
w
corollary. in the decoding tree there are at least two leaves of maximum depth that are siblings.
observation. (simple claim) there is an optimal solution in which the two symbols with lowest frequencies are assigned to leaves of maximum depth, and furthermore they are siblings.
proof. if we have but , note:
so we can always swap the two nodes and (original) (after). so lowest frequency symbols should appear at leaves.
algo:
R
0 / \ 1
s1 s2
(see cs240 - how are they different?)
correctness: use induction. base case is if there are 2 symbols, correct. if there are more than 2 symbols and our T' is optimal, for the new tree T after adding two symbols, . we want to show any other tree will have obj >= this.
suppose an optimal solution is . remove y and z from we have is a feasible solution to the reduced problem. since is optimal, we have . using same calculation we have (1). so we have .
(1) how can you use same calculation T* might not have w? use the y & z's common parent because they are sibling.
runtime: O(nlogn) (use heap for get min)
given a directed graph G=(V,E), a non-negative length for each edge , and two vertices . find a shortest path from s to v for every vertex .
using reduction:
we want to simulate this process, but don't want to follow broken edges step by step. we keep track of an upper bound on the time a vertex to be found.
5 1
f <------- s ------> g
| 2
b
algo (dijkstra):
dijkstra(G, s):
auto parents = {}
auto dist = {v: ∞ for v in G.V}
auto Q = new priority_queue
dist[s] = 0
for v, bound in dist:
Q.insert(v, key=bound)
while Q is not empty:
auto u = Q.delete_min()
for each out_v in u:
auto l = /*length of uv*/
if dist[u] + l < dist[out_v]:
dist[out_v] = dist[u] + l
Q.set_key(out_v, dist[out_v]) // "decrease_key()"
parents[out_v] = u // may be set multiple times
return ...
runtime:
puzzle. do not trust this; there are better formations than it
Instead of filling the priority queue with all nodes in the initialization phase, it is also possible to initialize it to contain only source; then, inside the if dist[u] + l < dist[out_v] block, the decrease_priority() becomes an add_with_priority() operation if the node is not already in the queue.
idea:
algo:
correctness: we want to show the following invariant holds: for any v in R, dist[v] is the shortest path distance from s to v.
proceed by induction. base case R={s}, then dist[s] = 0 is shortest. inductive: suppose R is computed correctly, now we have u, we want to show the shortest path from s to u is dist[v] + .
shortest path tree:
remark. algo breaks when length is negative. it fails at the ... in the proof.
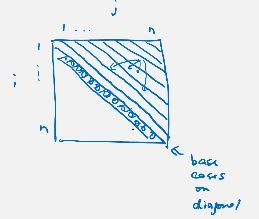
on a high level, we can solve a problem by dynamic programming if there is a recurrence relation with only a polynomial number of subproblems.
eg. how to compute ? we compute the same term too many times and the run time is O(1.618^n).
F(i):
if visited[i]:
return answer[i]
if i == 0 or i == 1:
return 1
answer[i] = F(i - 1) + F(i - 2)
visited[i] = true
return answer[i]
F(N):
auto F0, F1 = 1, 1
for i = 2, N:
F0, F1 = F1, F0 + F1
return F1
in principle, to come up with bottom-up implementation, we just need to use a topological ordering of the 'subproblem dependency graph' to have correct order to solve subproblems.
given n intervals and a weight for each interval i. find a subset of disjoint intervals that maximizes the total weight.
1 3 6 10
---- ------- ------ ----
---- -- -- 8 -----
2 4 5 9 ---
7 ----- ------- 11
note if we already pick 1 and 3 and wish to extend this solution. this is solves the same problem as having picked 2 and 3 - what really matters is the last interval of the current partial solution.
we use a good ordering of the intervals and precompute some useful info.
next(1) = 6 next(4) = 9
next(2) = 4 next(5) = 8
next(3) = 5 next(6) = 7
runtime (top-down):
we can use bottom-up computation too, from n to 1.
puzzle. how to print the intervals? (linked list to maintain linear time)
given n positives integers and an integer K. find a subset with or report no such subset exists.
a[1] = 3, a[2] = 2, a[3] = 7, a[4] = 8, ...
note after picking a[1] and a[3], we solve the similar subproblem as having picked a[2] and a[4].
D[i][L] = D[i + 1][L - a[i]] or D[i + 1][L]D[i][0] = true for all iD[i][L] = false if i > nD[i][L] = false if L < 0bottom-up:
for i = 1, n:
for L = 0, K:
D[i][L] = false
D[n][a[n]] = D[n][0] = true
for i = 1, n:
D[i][0] = true
for i = n, 1, -1:
for L = 1, K:
D[i][L] ||= D[i + 1][L]
if L - a[i] >= 0:
D[i][L] ||= D[i + 1][l - a[i]]
return D[1][K]
runtime: nK subproblems, in each subproblem, look up two values => O(nK) (pseudo polynomial).
remark. if decision problem, we can keep only two rows. space complexity becomes O(K) instead of O(nK).
remark. if using top-down, we do not necessarily compute all subproblems unlike bottom-up.
remark. D[1][K] is true iff there exists a directed path from (1, K) to some nodes with 'true' base case.
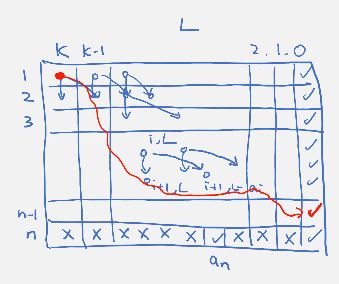
given n items, each of weight and value , and a positive integer W. find a subset such that that maximizes .
approach 1:
D[i][w][v] = D[i + 1][w][v] or D[i + 1][w - w[i]][v - a[i]]D[i][0][0] = true for all iD[n+1][w][v] = false for all w !=0 and v != 0max{ v: D[i][w][v] = true and w <= W }runtime: .
approach 2:
D[i][w] = max{ D[i + 1][w], a[i] + D[i + 1][w - w[i]] }D[n+1][w] = 0 for all w >= 0D[i][w] = -inf for all w < 0 (illegal)D[1][w]runtime: O(nW)
given n numbers , a subsequence is a subset with . a subsequence is increasing if . find an increasing subsequence of maximum length.
[5, 1, 9, 8, 8, 8, 4, 5, 6, 7] => 1 4 5 6 7
L[i] = 1 + max{ L[j]: a[j] > a[i] and i+1 <= j <= n }L[n] = 1 (take only one number)max(L)runtime: O(n^2)
how to print the sequences?
i | 1 2 3 4 5 6 7 8 9
--+-----------------------------
a | 3 8 7 2 6 4 12 14 9
L | 4 3 3 4 3 3 2 1 1
^ ^ ^ ^
we know answer is of length 4. trace L from 4 to 1.
or use parent array.
remark. if runtime == # of subproblems, then algo is likely to be optimal. otherwise there might be better algo.
idea:
define to be the best position to extend a subsequence of length k, and let be the length of a longest increasing subsequence we computed so far. then we only need L(pos[1]), ..., L(pos[m]) for future computations.
i | 1 2 3 4 5 6 7 8
--+------------------------
a | 2 7 6 1 4 8 5 3
L | 3 2 2 3 2 1 1 1
^ ^ ^
pos[1] = 6, pos[2] = 2, pos[3] = 1
claim. (monotone) a[pos[1]] > ... > a[pos[m]]: it is harder to extend a longer increasing subsequence than a shorter one.
proof. suppose by contradiction there exists j such that a[pos[j]] >= a[pos[j-1]]. assume we have the longest increasing subsequence =a[pos[j]] < of length j. then will be a position to start such a subsequence of length j-1. we have > a[pos[j]] >= a[pos[j-1]], which is a contradiction because would be a better place to start subsequence of length j-1.
algo:
auto m = 1 // length
pos[1] = n // base
for i = n-1, 1, -1:
if a[i] < a[pos[m]]:
++m
pos[m] = i
else:
use binary search to find smallest j st a[pos[j]] <= a[i] // < a[pos[j-1]]
pos[j] = i
return m
runtime: O(nlogn)
given two strings and , find the largest k such that there exist and for .
longest increasing subsequence is a special case of this problem, where the second array is the sorted version.
___ _
S1 = 3 1 2 8 9 7
___ _
S2 = 1 2 3 7 8 9
answer = 1 2 7
let C[i][j] be the length of a longest common subsequence of a[i]...a[n] and b[j]...b[m].
a[i] and b[j]:
a[i] == b[j], we include this in the subsequence: sol1 = 1 + C[i + 1][j + 1]a[i] a a a a a a
||
b[j] b b b b b b
sol1 = 0a[i] and skip b[j]: sol2 = c[i][j + 1] a[i] a a a a a a
x b b b b b b
b[j] and skip a[i]: sol3 = c[i + 1][j]C[i][j] = max{ sol1, sol2, sol3 }C[n + 1][j] = 0 for all jC[i][m + 1] = 0 for all ia[1][1]runtime: there are O(nm) subproblems, each takes constant time => total O(nm).
bottom-up: count i from n to 1, and count j from n to 1.
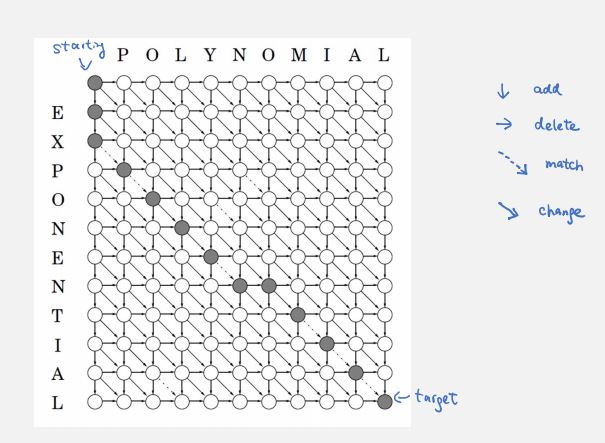
given two strings and , find the minimum k such that we can do k add/delete/change operations to transform to .
let D[i][j] be the edit distance of a[i]...a[n] and b[j]...b[m].
a[i] and b[j]:
sol1 = D[i + 1][j + 1]sol1 = infsol2 = 1 + D[i][j + 1]sol2 = infsol3 = 1 + D[i + 1][j]sol3 = infsol4 = 1 + D[i + 1][j + 1]sol4 = infD[i][j] = min{ sol1, sol2, sol3, sol4 }D[n + 1][m + 1] = 0D[1][1]runtime: O(nm).
bottom-up: dependency points bottom-right. we only have one corner base case, fill in the bottom row and rightmost column first.
puzzle. given DAG, what is length of longest path from s to t? order V by topo, let d[i] be the length of longest path from s to i, then d[i] = i == s ? 0 : max { d[j]: j and i and neighbors } + 1, answer is d[t].
defn. given a graph G=(V, E), a subset of vertices is an independent set if for all .
given a tree T=(V,E), find an independent set of maximum cardinality.
A -- B -- C -- D
sol: A and C, or A and D, or B and D. size 2.
we define subproblem as I[v] be the size of a maximum independent set in the subtree rooted at vertex v.
max{size1, size2}O[v] = 1 for all leaves vI[root]runtime: there are n subproblems. in total, we look at vertices. this is the same as .
puzzle. how to solve max weighted independent set problem?
J[v] = 1, M[v] = 0 for every leaf vmax{ J[root], M[root] }runtime: .
given n keys and non-negative frequencies . find a binary search tree T that minimizes .
note optimal solution does not necessarily require key with highest frequency at the top - have to respect bst structure.
let C[i][j] be the objective value of an optimal bst with keys .
C[i][i] = f[i], C[i][i-1] = 0 for all iC[1][n]runtime: n^2 subproblems, for each we take O(n) possibilities. total: O(n^3).
bottom-up: compute smaller width (j-i) first then larger subproblems.
better: Knuth's O(n^2).
given a directed graph G=(V,E), a length for each edge , and two vertices . find a shortest path from s to v for every vertex , assuming no negative cycles exist.
what is wrong with dijkstra's: if we suddenly find a negative edge that decreases the distance to a visited vertex m, then all vertices that are reached by m have to be updated.
1 5
s -----> a -----> b -----> c
| ^
v | -1000
g -----> h
100
if there are no negative edges, after deciding sa and dropping sg, we instantly know sa is
shortest to reach a. however, if negative edges exist, we cannot drop sg as ah makes it smaller.
update a, b and c!
negative cycles: shortest path distance is not well-defined if a cycles consisting of negative edges appear in the middle of path.
-1
s -----> a -----> b ------> t
-1 | ^
v -1 | -1
c ------+
we can keep walking in the cycle - the dist is not bounded below
idea: dijkstra will compute distance to some vertices correctly eg. first vertex on a path
let D[v][i] be the shortest path distance from s to v using at most i edges.
D[s][0] = 0D[v][0] = inf for all v except sD[v][n-1]runtime:
space: O(n^2) (O(n) if just want distance, only keep D[v][i+1] and D[v][i])
algo (bellman-ford):
dist[s] = 0
for v in V - {s}:
dist[v] = inf
for i = 1, n-1:
for each edge uv in E:
if dist[u] + L[uv] < dist[v]: // relaxation step
dist[v] = dist[u] + L[uv]
parent[v] = u
lemma. if there is a directed cycle C in the edges (parent[v], v), then C must be a negative cycle.
proof. assume there is a directed cycle where the final edge is (parent of is ). then for , the for loop tells us . if we added the edge , we also have . adding the inequalities we get , which only happens for negative cycles.
given a directed graph G=(V,E), a length for each edge . find a negative cycle.
note D[v][i] is computed correctly even though graph can have negative cycles (we only used such assumption in last question for computing stopping condition).
idea:
claim. D[v][n] = D[v][n - 1] for all iff G has no negative cycles.
proof.
remark. early termination rules is D[v][k+1] = D[v][k] for all v.
hence for checking, using the above claim we can do bellman-ford with an extra iteration step.
claim. if D[v][n] < D[v][n - 1] for some v, then in the walk (by tracing parent) between two repeated vertices we find a negative cycle.
proof. then we know the shortest path using at most n edges to get to v must have exactly n edges (otherwise D[v][n] = D[v][n-1]). so there is at least one repeated vertex, meaning there is a cycle in the walk. we suppose otherwise that this cycle is not negative, then D[v][n-1] <= length(W') <= length(W) = D[v][n], where W' is done by using n-1 edges and W is done using n edges. this is a contradiction.
given a directed graph G=(V,E), a length for each edge . find shortest path distances from s to t for all . assume no negative cycles exist.
naive: use bellman-ford for all s. time is O(nm*n) (account for # edges!).
define D[i][j][k] to be the shortest path distance from to using as intermediate vertices.
+--> k+1 --+
^ | using {v[1], ..., v[k]}
using {v[1], ..., v[k]} | v
i ---------> j
d[i][j][k] = min{ D[i][j][k], D[i][k+1][k] + D[k+1][j][k] }D[i][j][0] = l[ij] for all edges D[i][j][0] = inf for all D[i][j][n] for all i, jalgo (floyd-warshall):
D[i][j][0] = inf
for all edge v[i]v[j] in E:
D[i][j][0] = l[ij]
for k = 1, n:
for i = 1, n:
for j = 1, n:
d[i][j][k] = min(D[i][j][k], D[i][k+1][k] + D[k+1][j][k])
runtime: O(n^3)
puzzle. reduce one dimension of D by using adj matrix?
given a directed graph G=(V,E), a length for each edge . find a directed cycle C that visits every vertex exactly once that minimizes .
naive: try every combination of vertices and compute weights (O(n!)n).
define C[i][S] to be the shortest path distance from 1 to with vertex set on the path.
runtime:
defn. a subset of edges is a matching if edges in M are pairwise vertex disjoint.
defn. given matching M, a vertex v is matched if v is the endpoint of some edge , otherwise v is unmatched/free.
defn. a matching M is a perfect matching if every vertex is matched in M.
given a bipartite graph G=(X,Y;E), find a maximum cardinality subset of edges that are vertex disjoint.
defn. a path is an augmenting path with respect to a matching M if
we always have a partial solution (greedily), if we find an augmenting path, then we can remove middle (even) edges and add (odd) edges to increase size of matching by 1.
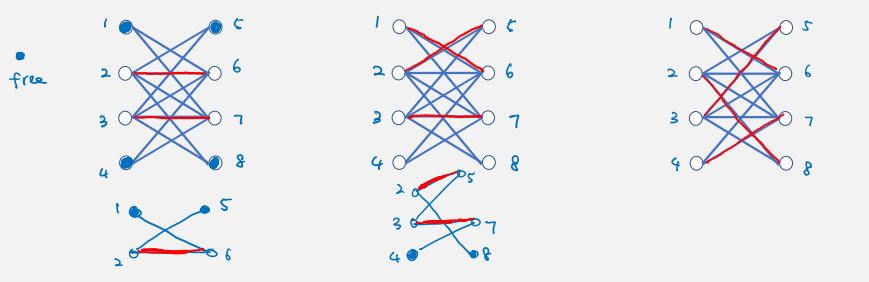
prop. there is augmenting path with respect to M iff M is not a maximum matching.
proof.
case 1: common edges
+-----+
x y
+=====+
case 2: path with more == than --
+----y u
|| || ||
x z --- t
case 3: path with same == and --
+----y u ---- v
|| || ||
x z --- t
case 4: path with more -- than ==
+----z v ---- s
|| || ||
x --- y t --- u
case 5: cycles with same == and --
x --- y
|| ||
z --- t
algo:
runtime:
faster: (edmonds and karp)
given a bipartite graph G=(X,Y;E) and a matching M. find an augmenting path of M in G or report it does not exist.
because we have bipartite graph, we use directions to encode matching information. we assign one direction (from right to left) for all edges in M, and the other direction for unmatched edges (). then we can follow the directed alternating path.
claim. there exists an augmenting path of M in G iff there exists a directed path from a free vertex on the left to a free vertex on the right in .
proof. clear.
naive: do bfs on each free vertex on left (O(nm)).
we can add pseudo source and target nodes connected to free vertices to avoid enumerating all pairs. source in X, sink in Y.
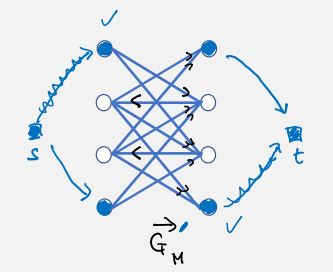
claim. there is an augmenting path of M in G iff there exists directed path from s to t in .
proof.: clear, just remove s and t from final answer.
algo:
runtime: O(m+n).
puzzle. how to find maximum matching in general graphs? finding aug path step will break. (edmonds)
defn. given graph G=(V,E), a subset of vertices is a vertex cover if for all .
given a bipartite graph G=(X,Y;E), find a vertex cover of minimum cardinality.
observation. (lower bound of vertex cover) if we have any matching M, and any vertex cover S, then .
x z u s
| | |
y t v matching of size 3, use at least 3 vertices to cover
theorem. (könig) in a bipartite graph G(X,Y;E), max size of a matching is equal to the min size of a vertex cover.
proof. only need to consider the upper bound of |S|, ie suppose we run the matching finding algo and find a max matching M; we want to show . since M is maximum, in , we cannot find a path from super source s (in X) to super sink t (in Y). let R be set of reachable vertices from s, then there are no edge with tail in R and head in (otherwise that edge will go to R from s). note also if R does not include some vertex in M, then it cannot include the corresponding matching pair - ie . this is because each has indegree = 1 and outdegree = 0, and its only in-neighbor is ; reaching one implies reaching the other.
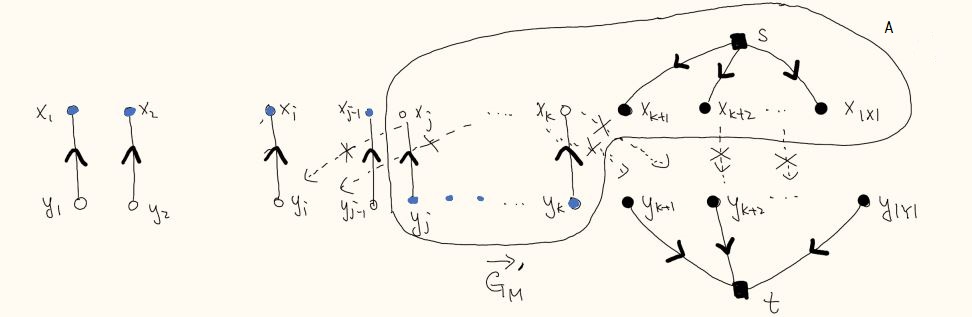
then set is a vertex cover, where will cover all edges with endpoint in , and will cover all edges with endpoint in (this is all types of edges in bipartite graph). (how to show it is minimal?)
remark. how to show perfect matching does not exist? vertex cover size is less than n/2.
algo:
runtime: O(T(matching) + m+n)
theorem. (hall) a bipartite graph G=(X,Y;E) with |X|=|Y| has perfect matching iff for all , we have where N(S) is the neighbor set of S in Y.
pf. use könig.
corollary. every d-regular bipartite graph G=(X,Y;E) has perfect matching.
pf. use könig.
remark. randomized O(nlogn) algo exists to find it.
puzzle. capacitated job assignment (each vertex in Y has capacity)? create copies of vertices according to its capacity. number of vertices becomes |X|+O(|X||Y|), number of edges becomes O(|X||E|).
given the current standing and the remaining schedule, tell whether it is possible that a team can still win in the league.
standing remaining schedule
W L Miami-Boston x3
Boston 41 17 New York - Boston x2
New York 40 18 ...
Philadelphia 38 19 Toronto - New York x2
... ...
Toronto 33 25
idea: assume toronto win all its remaining games and in total wins. we want all other teams win less than games. say team i currently has wins, we want it to win no more than games.
create bipartite graph, one side is the teams with their capacity = their max wins, one side is games (each with two edges going to two teams). we will want to find a way to assign each game a winner. if such assignment exists, then toronto is possible to win.
remark. it is hard for football games (draws)
find the maximum number of edge-disjoint paths between two vertices s and t (different paths can not use same edge).
if we find a 'cut' of k edges, then the maximum number of flows from s is k.
replace integral constraints to linear constraints . 0 means not picked. gibstic
augmenting path method can be understood as the simplex method of solving linear programs.
it is more convenient to restrict to decision problem so that every problem has same output format. if we know how to solve decision version of the problem in polynomial time, then we can use the decision algorithm as blackbox/subroutine to solve the the search version of problem in polynomial time.
eg. find a max bipartite matching.
defn. a decision problem A is polynomial time reducible to decision problem B if there exists a polynomial time algorithm F that maps any input instance of A into an input instance of B such that is a YES-instance of problem A iff is a YES-instance of problem B. we write when such a polynomial time reduction exists, saying A is not more difficult than B in terms of polynomial time solvability.
algo (solving problem A by reduction):
runtime: F maps to in , solves in . total .
corollary. if A cannot be solved in polynomial time, then B cannot be solved in polynomial time.
prop. (transitivity) if and , then .
proof. transform to then to .
maximum clique (Clique):
defn. a subset is a clique if for all .
decision version: given graph G=(V,E), is there a clique with at least k vertices?
maximum independent set (IS):
decision version: given graph G=(V,E), is there an independent set with at least k vertices?
minimum vertex cover (VC):
decision version: given graph G=(V,E), is there a vertex cover with at most k vertices?
prop. and .
proof.
prop. and
proof.
so all three problems are equivalent in terms of polynomial time solvability.
hamiltonian cycle (HC):
defn. a cycle is hamiltonian if it touches every vertex exactly once.
decision version: given graph G=(V,E), does G have a hamiltonian cycle?
hamiltonian path (HP):
defn. a path is hamiltonian if it touches every vertex exactly once.
decision version: given graph G=(V,E), does G have a hamiltonian path?
traveling salesman problem (TSP):
decision version: given graph G=(V,E) with an length for each edge , is there a hamiltonian cycle with total length at most ?
prop. .
proof. define reduction , where s is an additional vertex that goes to every existing vertex. claim G has a HP iff G' has a HC.
prop.
proof. define reduction where is arbitrary. claim G has a HC iff G' has a HP.
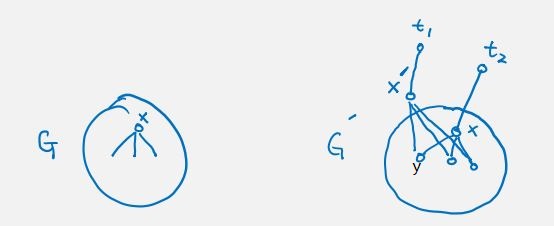
prop. .
proof. define transform such that is complete graph, and . claim G has a HC iff G' has a HC of total length at most .
note (in hw) also need to show these transformations are done in polynomial time.
remark. it is not clear how to reduce TSP to HC.
given n boolean variables which can be either True or False, and a formula in conjunctive normal form (CNF) where it is an AND of the clauses where each clause is an OR of the literals where a literal is either or .
if each clause has at most 3 literals, is there a truth assignment to the variables that satisfies all the clauses?
theorem. .
proof. given a 3SAT formula, we would like to construct a graph G so that the formula is satisfiable iff the graph has an independent set of size m where m is the number of clauses. for each clause, we connect at most three vertices corresponding to the literals (so single vertex/pair/triangle) (ensure in each clause we satisfy one literal). we also connect vertices (to prevent both of them appearing in the independent set at same time).
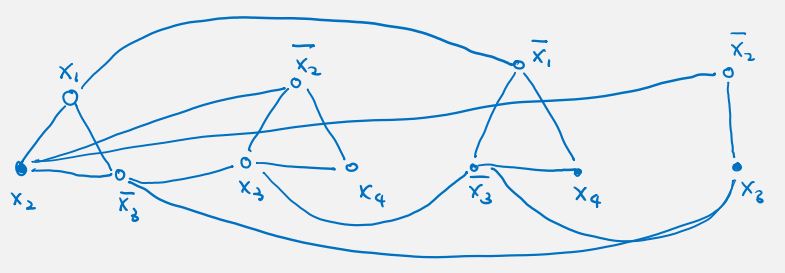
remark. it is not important how many literals in a clause.
it is not easy to compare every pairs (O(n^2)) of problems to see if they can be reduced to each other. we can identify the 'hardest' problems in a large class of problems.
a general feature of problems is that there is a short 'proof/solution' of a YES-instance - it is easier to verify.
defn. for a problem X, each input instance of X is represented by a binary string s. a problem X is in the class NP if there is a polynomial time verification algorithm s.t. the input s is a YES-instance iff there is a proof t which is a binary string of length so that returns YES.
input s --> +----+
| Bx | --> YES/NO
proof t --> +----+
eg. show vertex cover is in NP.
we are given graph G and an integer k. we encode (G, k) into a binary string s, and t into a binary string of . let be algo that takes s and t as input and checks if every edge is covered by with size <= k. then says yes if S is vertex of size <= k, and says NO if t does not correspond to a vertex cover of size <= k.
eg. show 3SAT is in NP.
we are given a truth assignment (size <= n). algo: check if it is satisfying (runtime O(m)) where m is number of clauses. iff is clear.
remark. Clique, IS, HC, HP, subset-sum are all in NP.
remark. (non-HC) we do not know a short proof how to show graph has no HC.
defn. X is in co-NP if there is short proof and an efficient verification for NO-instances.
eg. bipartite matching (at most size k) is in both NP and co-NP.
for NO-instances (asking does G have graph has no matching >= k?), by konig, it is the same a asking 'whether G has vertex cover of size < k?', which is easy to check.
remark. it is common belief .
remark. . if problem can be solved in poly time, it is trivially in NP (do not even need another t and ).
remark. our NP definition is equivalent to saying "NP is class of problems solvable by a non-deterministic turing machine in poly time".
remark. it is common belief .
defn. a problem is NP-complete if for all .
prop. P=NP iff an NP-complete problem can be solved in polynomial time.
to prove a problem X is NP-complete, we first show X is NP, then find an NP-complete problem Y show . (common mistake is showing X <=p Y)
we introduce an intermediate problem to show 3SAT is NP-complete.
circuit-SAT: given a circuit with AND/OR/NOT gates, some known input gates and some unknown input gates, assuming input circuit is DAG, and each AND/OR gate has only two incoming edges.. is there a truth assignment on the unknown input gates so that the output is True?
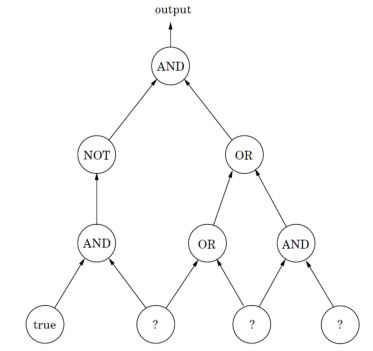
theorem. circuit-SAT is NP-complete.
pf. we want to show for all NP problem X we have . we start from the definition of NP (algorithm satisfaction: there exists a verification program that runs in poly time), and try to use a poly-time compiler to turn the verification algo into a circuit of poly size so that the circuit says YES if given input s and proof t is for YES instances, and NO if the problem's answer is NO no matter what proof is given. then input s is a YES-instance iff there is a satisfying assignment for Circuit-SAT.
theorem. .
pf. given circuit of n gates, we will construct a 3SAT formula with O(n) variables so that circuit is satisfiable iff the formula is satisfiable.:
true --> a
false --> b
a --> NOT --> b
a -->
AND --> c
b -->
a -->
OR --> c
b -->
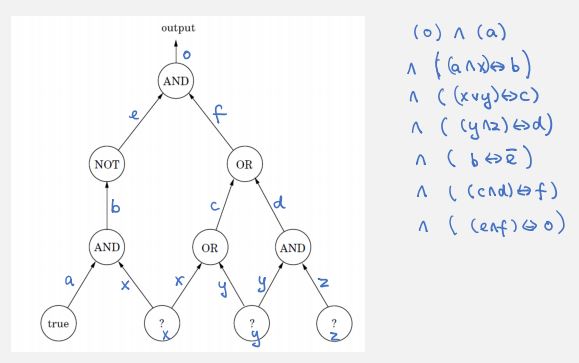
it is clear we can turn the circuit into a 3SAT formula in poly time in terms of size of circuit (# of gates/edges). plugging in x, y, z into the circuit, and simulate the circuit behavior regarding gates, then the resultant variables satisfy the formula too. if there is assignment of the formula, plugging them into the circuit will make the circuit happy as well.
theorem. (cook-levin) 3-SAT is NP-complete.
defn. a directed cycle is a hamiltonian cycle if it touches every vertex exactly once.
directed hamiltonian cycle (DHC): given directed graph G=(V,E), does G has a DHC?
theorem. DHC is NP-complete.
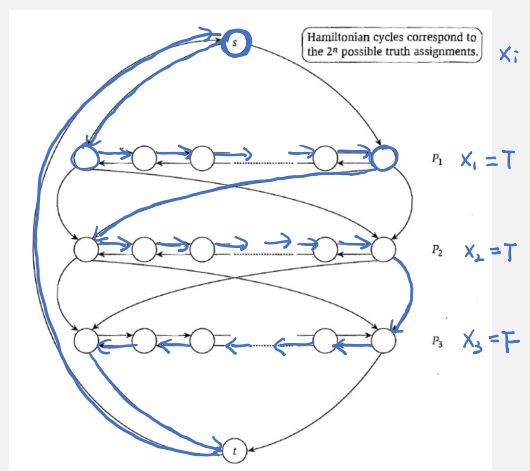
proof. it is easy to check DHC is in NP. we now will show , ie given a 3SAT formula with n variables and m clauses , we would like to construct a directed graph G so that formula is satisfiable iff G has a DHC. we create a long 'two-way' path for each variable, so that going the path from left to right corresponds to setting variable to True, while from right to left corresponds to setting it to False.
now a hamilton cycle in G has one-to-one correspondence with an assignment. now we want to add clause structures so that only satisfying assignments 'survive'. for each clause, we create a separate vertex. depending on whether literal is negated, we assign different directions for edges that go to the clause vertex (thus forcing the left/right direction of each ). note clause vertex only has edges to the portions reserved for the clause.
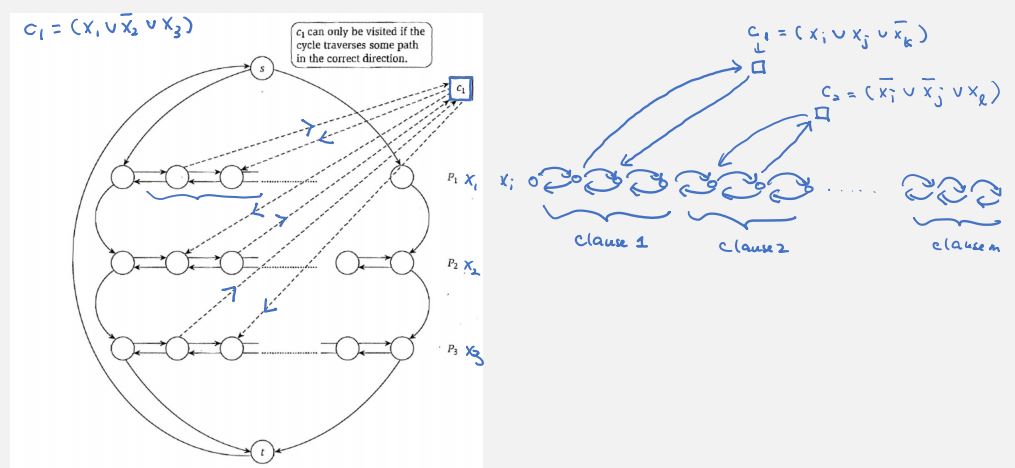
prop. .
proof. given input directed graph G, we use a length 3 path to simulate a directed edge. for each vertex in G, we create 3 vertices connected with two middle edges, and has original in-edges in G, has out-edges. we claim G has a DHC iff G' has a HC.
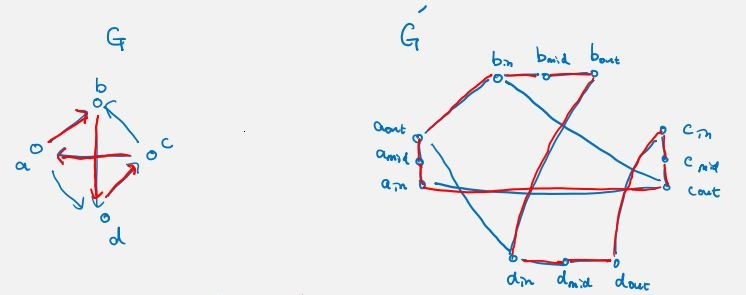
it is clear if G has a DHC, we can follow it in G' to form a HC. suppose we have a HC in G' and it starts from , then must goto , then to , then go to some other , .... if we shrink each three vertex we get a DHC in G. (having mid vertex forces a path to go to it onces it touches some in vertex , otherwise it may just leave if some other goes to , which is not what we want it to behave)
corollary. HC is NP-complete.
given undirected graph G=(V,E) and positive integer k, is it possible to use k colors to color all vertices so that every vertex receives one vertex and any two adjacent vertices receive different colors?
theorem. 3-coloring is NP-complete.
proof. it is easy to check 3-coloring is in NP. we want to show , ie given a 3SAT formula with n variables and m clauses , we would like to construct a graph G so that formula is satisfiable iff G is 3-colorable. we associate True and False as two colors. for each variable , we create two vertices and add an edge between them so they get different colors. to enforce they get True/False colors, we connect every literal vertex to a common vertex called base vertex colored using color B.
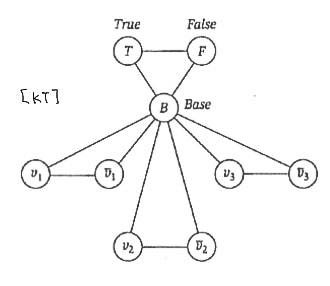
so there is 1-1 correspondence between truth assignments and the 3-colorings.
we now involve clauses so that only satisfying assignments remain. we can use a 'gadget' to connect to the three variables in the clause so that there is a 3-coloring for the gadget iff at least one of them gets the color T. say we have clause , after trail-and-error, we can attach the following gadget to the base graph:
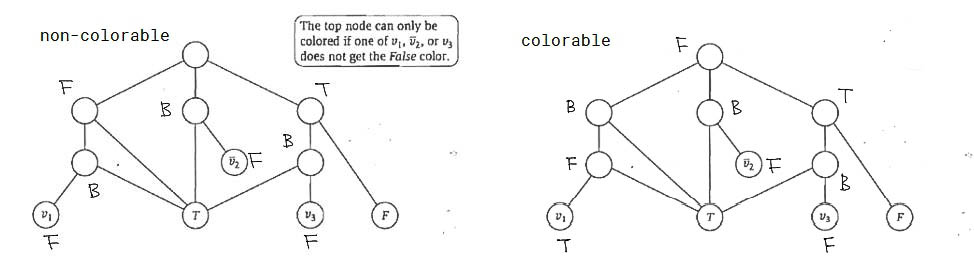
vertices with no labels mean they are added only for this clause. then suppose all are colored F => meaning clause is not satisfied. then all colors of vertices are forced, we cannot color the top node using any color. if any of them is colored T, then the top vertex can be colored using the 3 colors (check).
given disjoint sets X, Y, Z each of size n, a set . does there exist a subset of n disjoint triples in T (cover every element exactly once)?
a subset of n disjoint triples is called perfect 3d-matching.
x1 -- y1 -- z1
x2 -- y2 -- z2
x3 -- y3 -- z3
T={(x1,y1,z1),(x2,y2,z2),(x3,y3,z3)}
theorem. 3DM is NP-complete.
proof. it is easy to check 3DM is in NP. we want to show , ie given 3SAT formula with n variables and m clauses , we would like to construct a 3DM instance (hypergraph) so that the formula is satisfiable iff there is a perfect 3d-matching. for each variable , we create enclosed in a gadget. the 's are private to this variable and 's might be open. we have to cover a triple at a time and we try to cover all private nodes (cores).
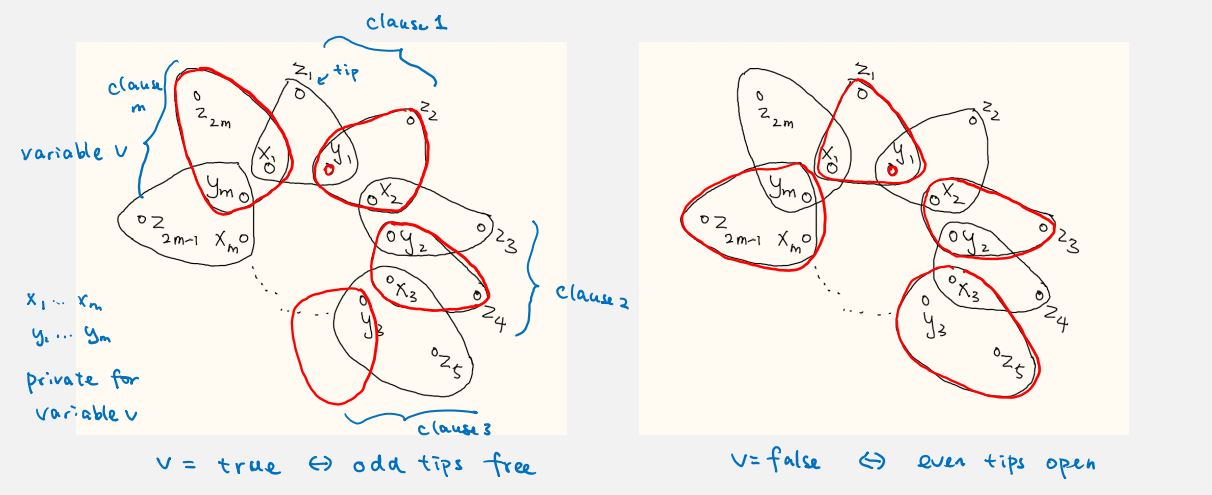
if three nodes are in a circle, it means such combination is possible (in T). note we have 2m 's as we reserve 2 's for each clause, half of them is used to cover triples and half is open.
so we have 1-1 one correspondence between the value of a variable and how private nodes are covered. we have n such flowers corresponding to n variables.
we now add some clause structure to the 3dm instance so that only satisfying assignments survive. the clause structure for each clause contains and can contain a free from the existing flowers, reserved for that clause.
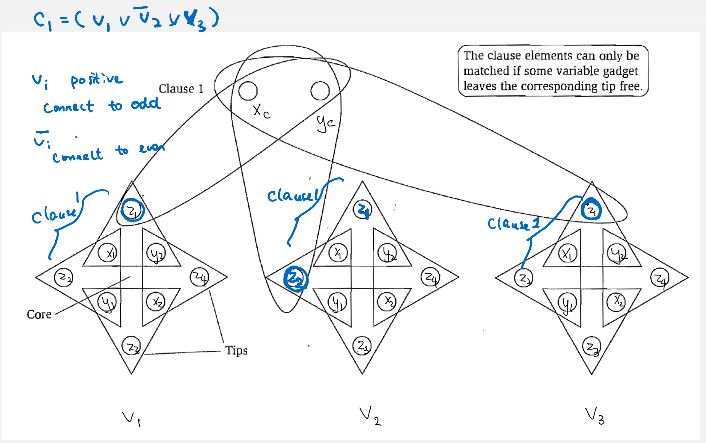 ]
]
at this point we have totally 2mn tips, # of tips covered by clauses is m. we have (2n-1)m tips left to cover (how about already-covered 's in each variable? should you minus mn?). we add this number of 'dummy' clauses which can form triples connecting two dummy nodes and one free like they were clauses.
given n positive integers and an integer K, does there exist a subset with ?
theorem. Subset-Sum is NP-complete.
proof. it is easy to check it is in NP. we want to show ., ie given 3DM instance, we would like to construct a subset-sum instance so that there is perfect 3d-matching iff there is subset of certain sum K. we naturally represent each triple as a vector: if node is used in a triple, in the vector it has 1 else 0.
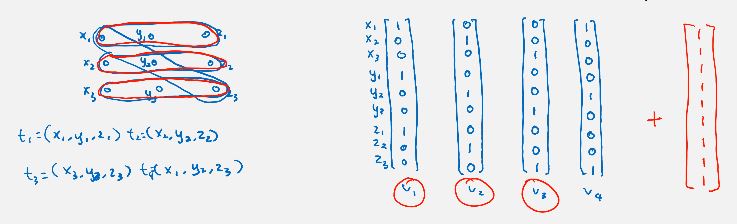
vector Subset-Sum: given a set of n 0-1 vectors, does there exist a subset of vectors that sum to ? we can see there is a perfect 3DM iff there is a subset of vectors summing to . so this vector Subset-Sum is also NP-complete.
to turn this vector Subset-Sum into Subset-Sum, we map each 0-1 vector to a base (m+1)-numbers, then , where m is number of available triples in 3DM (|T|).
remark. to turn this vector Subset-Sum into Subset-Sum, we could interpret the 0-1 vector as the binary representation of a number, then .
but reverse is not true <~ carrying may happen eg. 01+01+01=11=01+10. so we need base m+1 to avoid this.
corollary. knapsack is NP-complete.
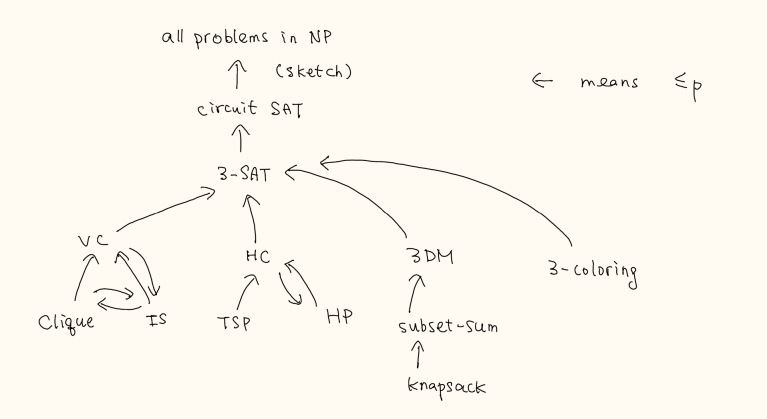
techniques for doing reductions: